
Ready to Race?
RPM® 极速赛车168在线记录查询-观看赛车历史记录-最新一分钟赛事记录结果168网





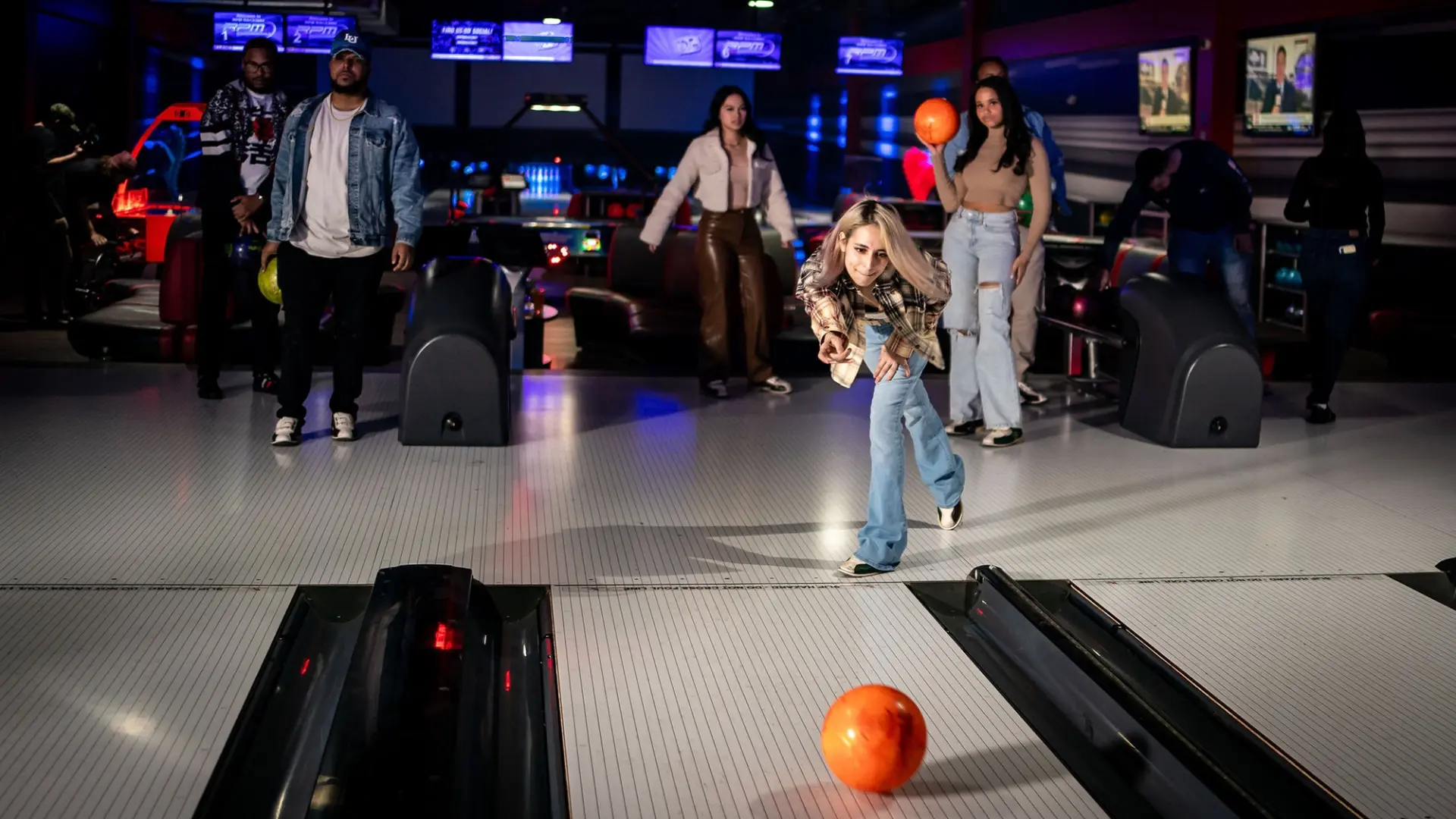

极速赛车168开奖官方开奖网站查询结果
Works

Create your official RPM Racer profile online or visit one of the registration kiosks when you arrive. Select your racer name, pick your avatar, and be sure to give us your correct email so that you can receive all your racing results!

Race our most popular racing format, competing for the fastest lap time. Our real-time scoring will give you a lap-by-lap breakdown and benchmark your personal scores to other track legends.

Champions never race on an empty stomach. Enjoy a foodie experience with custom small bites, hand-crafted burgers, brick oven styled pizzas, little green gems, decadent sweets and so much more.

Play in our out-of-this-world arcade center featuring immersive reality experiences + redemption arcade with all your favorite cult classics & modern games. Rack up points to get special prizes... and trust us, these are prizes YOU'LL WANT to take home!

Every 在线一分钟查询极速赛车结果历史官网 Starts in a Kart.
Feel the thrill of our electric go-kart racing as you race on our multilevel & LED tracks crafted for pure exhilaration. Our tracks feature spiraling ramps, sudden dips, drops, underpasses, and lightning-fast straights. Our tracks are designed by top European track developers, and raced by some of your favorite F1 legends.

Non-Stop Fun.
极速赛车官网结果历史记录-168网站直播视频-超级赛车信誉平台-this-world virtual & augmented reality experiences for our guests. Step into Hologate or Hyperdeck to fight zombies, try your luck at digital darts, hit a strike in the bowling alley, or set some high scores in our redemption arcade!
Your party.Our track.
Corporate Events
Kids Birthday Parties
Adult Parties
Charity Events
Bar Mitzvah’s
Getting people together for a good time is what we do best. Whether it's a birthday bash, corporate event, or a fundraiser, RPM offers a one-of-a-kind setting to entertain your friends, family, and colleagues!





Start planning your custom event package!
Customer 中国历史赛事+赛车比赛游戏网站官网查询
Promotions & Events























Give the 极速一分钟赛果查询记录号码
of Speed.
一分钟极速赛车彩票数据 open the doors to an unforgettable time with your friends and family. From the track to the arcade, to our bowling alley, there's a variety of ways to get the most out of your RPM Gift Card.
Purchase Gift Card











Sign up for RPM® newsletter
极速赛车168历史优势平台免费提供 168开奖官网开奖视频顶级欧洲开发商设计的多层LED赛道上-最新一分钟赛事记录结果168网、极速赛车168在线记录查询-观看赛车历史记录-75秒现场数据体验电动卡丁车竞速的激情与刺激!